0x01 前言
上篇文章 Too many open files 错误深度分析 中,我们讲了linux内核对每个进程,限制了其最大可打开的文件数,但该数量对于一般的服务进程来说是远远不够的,所以我们又介绍了n种方式,可使内核放宽对进程的这种限制,同时,我们也讲了这n种方式的内部原理。
在这篇文章中,我们就用单机单服务进程接收百万tcp连接的方式,来实践验证下前面文章中提到的各种理论,同时,我们也可以看下,在这过程中还会不会遇到其他问题。
0x02 疑问
在内核中,端口是用无符号16位整型表示的,它的范围是0到65535,其中0是特殊端口,表示让内核为应用程序挑选可用端口,它不能当作真正的端口来使用,所以在操作系统内部,可用的端口就只有65535个,那只用这65535个端口,又如何建立百万tcp连接呢?
这里有几个误区。
第一个误区是,大家可能会认为,内核在接收到一个tcp连接后,会为其分配一个新端口,其实不是这样的,内核接收到的tcp连接的本地端口,和其对应的服务进程中listener监听的端口是一样的,并不是每接收一个连接,内核都会为其分配一个新端口,且这些连接的本地ip地址,就是客户端在连接这个listener时,指定的ip地址。
看个例子:

上面是一段用rust写的测试代码,逻辑非常简单,就是在接收到tcp连接后,输出其本地地址和远端地址,然后再将其关闭。
运行上面的测试程序,然后用ncat命令对其建立tcp连接:

看下测试程序的输出:

由上图可见,local_addr中的端口都是9999,和listener监听的端口一样,而local_addr中的ip则是ncat命令建立tcp连接时指定的ip。
另一个误区是,大家认为操作系统是通过本地端口,或者是通过本地ip加本地端口,来唯一确定一个tcp连接的。
对于一般机器来说,只有一个ip地址,所以ip部分是不可变的,可变的只能是端口部分,而可用端口数上面我们也提到过,是65535个,所以推论为,一台机器最多可以建立65535个tcp连接。
这个观点其实是错误的,内核实际上是通过 [local_ip, local_port, peer_ip, peer_port] 四元组来唯一确定一个tcp连接的。
在这个四元组中,local_port部分是不可变的,它和listener监听的端口一样,但其他三个部分都是可变的,所以一个操作系统,理论上可以建立远不止万亿级别的tcp连接数。
0x03 实验
前面我们从理论上,证实了单机实现百万tcp连接的可行性,那在本节中,我们就亲自动手实验看下。
为了保证能有个干净的实验环境,我们用购买的云主机来测试。
我是在 Vultr 上购买的云主机,操作系统是Ubuntu 23.04,配置是1核1G内存,购买时记得为主机多添加几个vpc网络,这样一台主机上除了有一个默认的外网ip,还会有多个内网ip,有了更多的ip,就可以建立或接收更多的tcp连接了。
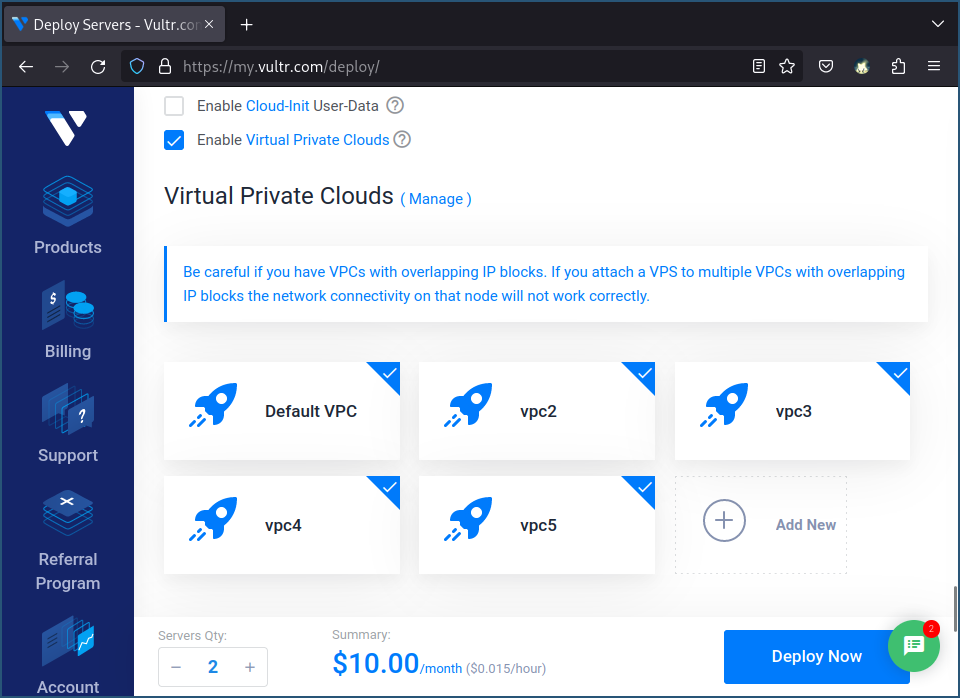
购买的2台机器,一台用作服务器,一台用作客户端,启动好后,看下机器信息,下面是服务器的:

看上图中,这台机器除了 127.0.0.1 外,有6个可用的ip地址,可以和客户端机器相互连通。
测试程序还是用 Too many open files 错误导致服务器死循环 文章中提到的 too-many-open-files ,该程序的客户端会不断的建立tcp连接到服务端,如果连接报错,会sleep一段时间,然后再继续尝试。
当连接成功后,客户端会每隔一段时间发送一些数据到服务端,服务端接收到数据后,会立即写回相同数据到客户端,用这样的方式,来验证已建立连接的健康性。
在连接建立期间,客户端和服务端也会输出各种日志,来记录各种信息,比如当前已建立的连接数,如果在上述流程中有错误发生,还会记录该错误的产生原因。
以上就是测试程序的大致逻辑。
在运行测试程序之前,我们先把两台机器上的防火墙关掉,下面只演示服务端机器上执行的命令:

然后把测试程序传到两台机器上,并在服务端机器上执行以下命令启动服务器:

在客户端机器上执行以下命令启动客户端,注意要指定正确的服务器地址:

看下服务端的输出:

看下客户端的输出:

上面两张图中显示,服务端和客户端都遇到了上一篇文章中讲到的 too many open files 错误。
我们可以用以下命令查看下,它们进程的文件描述符是否都已经用光。
先查看服务端的:
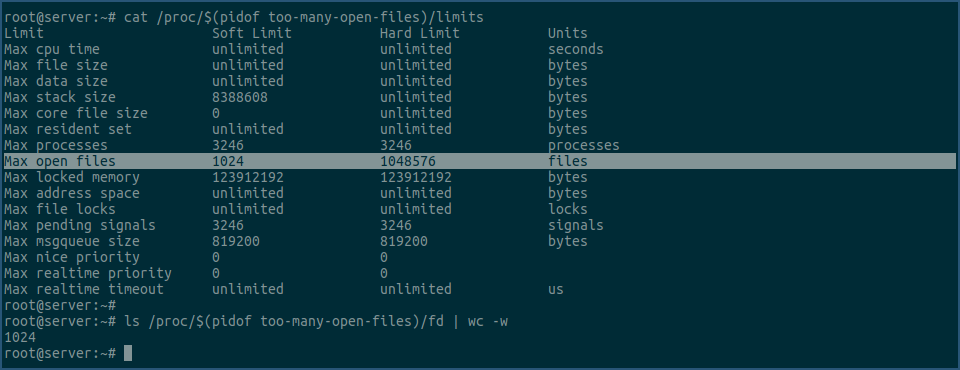
再查看客户端的:

通过上面两张图的输出可知,服务端和客户端进程的最大可用文件描述符数都是1024个,且都已用了1024个,所以继续建立或接收tcp连接,会产生 too many open files 错误。
在解决这个问题之前,我们先看另外一个问题,看上面服务端和客户端控制台的输出,服务端显示已建立了1014个连接,而客户端显示已建立了1015个连接,为什么差了一个呢?
这是因为服务端有个listener socket,它占了一个文件描述符,所以在服务器启动成功后,其可用的文件描述符数只剩1014个,即其可接收的tcp连接数是1014个,而客户端因为没有这个listener socket,所以可以创建1015个tcp连接。
那既然服务端只能接收1014个tcp连接,客户端为什么会显示成功建立了1015个tcp连接呢?
实际上服务端也成功建立了1015个连接,但因为文件描述符的限制,只能accept出来1014个,另一个还在内核的listener的等待accept队列里。
我们可以用以下命令来验证下:

看上图中选中行 Recv-Q 那一列,它的值是1,表示还有一个tcp连接,在内核的listener的等待接收队列里,未被accept出来。
既然listener有等待接收队列,那它的长度是多大呢?
这个值是由listen系统调用的backlog参数指定的,看下我们正在使用的rust测试程序里调用listen地方,backlog传入值是多大:
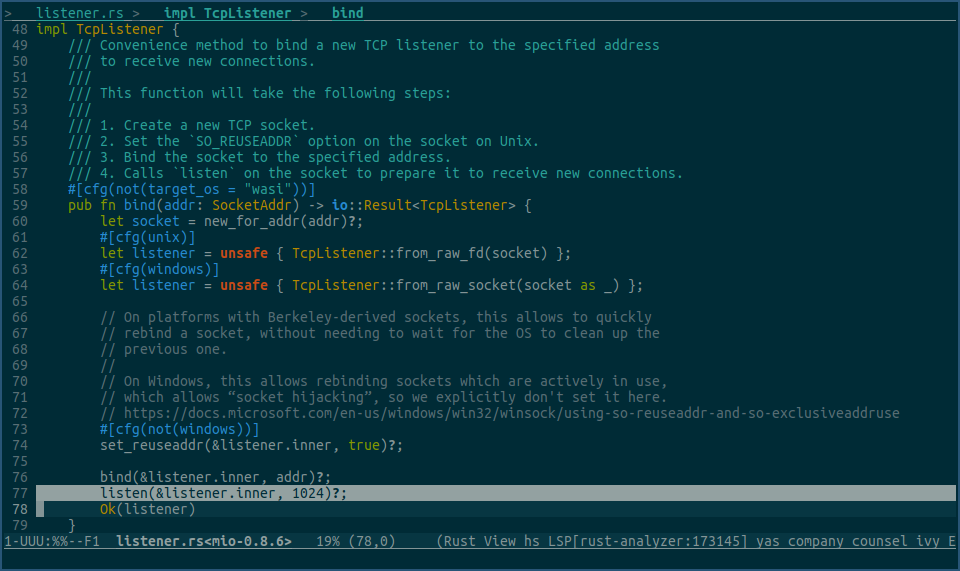
看上图的选中行,backlog值为1024,说明即使服务端的listener不调用accept接收tcp连接,内核还是可以为我们提前建立好1024个连接,放在listener的等待接收队列里。
真的是这样吗?我们来动手测试下。
我们先把客户端机器的进程最大可用文件描述符数,调成一个比较大的值,使其不会限制客户端建立tcp连接。

运行客户端测试程序,这次建立了2039个连接,之后再建立tcp连接,就会显示超时:

此时,服务端因为文件描述符的限制,还是只能accept出来1014个连接,我们看下此时listener的等待接收队列里有多少个连接:

还是看选中行的 Recv-Q 列,它显示还有1025个tcp连接等待被accept。
服务端已经accept出来的1014个连接,再加上这1025个未被accept出来的连接,正好等于客户端控制台显示的,已建立了2039个连接。
但是不对啊,我们上面提到过,测试程序在调用listen函数时,传入的backlog参数是1024,那在队列中未被accept出的最大连接数不应该是1024个吗?
看下内核代码:
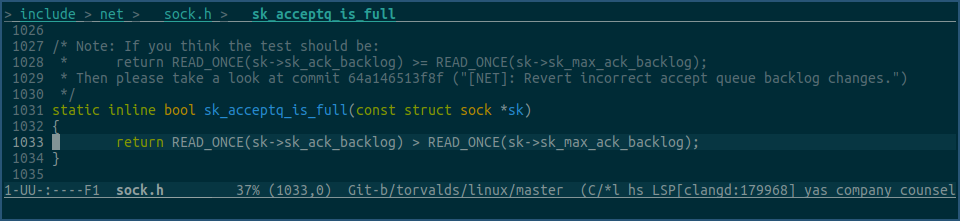
上图中的函数,就是用来判断listener的等待接收队列是否已经满了,其中 sk->sk_ack_backlog 字段表示已完成3次握手,并且已放入等待accept队列的tcp连接数,sk->sk_max_ack_backlog 字段是我们在调用listen函数时,传入的backlog值。
注意,该函数在比较这两个字段时,用的是大于,而不是大于等于,所以当等待接收队列中的tcp连接数为1024个时,该函数还是会返回false,表示队列未满,直到再有一个tcp连接,连接上来并放入队列,该函数才会返回true,表示队列满了,不能再接收其他tcp连接了。
这就是为什么我们的测试程序在调用listen函数时,传入的backlog值是1024,但实际上却可以在其等待接收队列里存放1025个tcp连接的原因。
其实该函数的注释,也解答了这个疑问,因为就曾经有人把它改成了大于等于,然后又被改回来了,看下这个revert commit的内容:
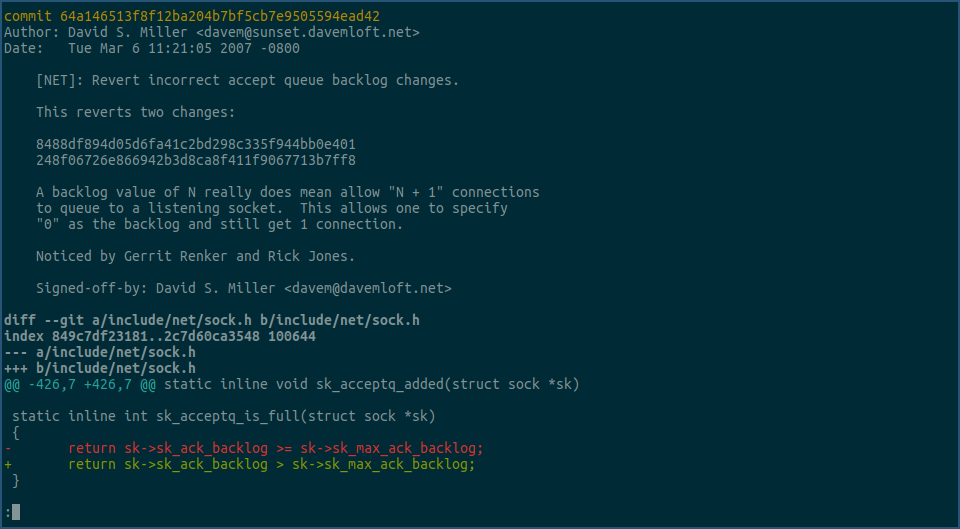
它说的是,之所以backlog值为n,允许n+1个连接放入等待接收队列,是因为当n为0时,仍然可以建立连接。
以上就是我们因为一个小疑问,引出来的一系列问题,以及对这些问题的解答,现在我们回到正题,继续尝试建立百万tcp连接。
上文提到,客户端和服务端在建立tcp连接的过程中,都遇到了文件描述符不够用的问题,所以都报了 too many open files 错误,那我们就用上篇文章中提到的方法,为客户端和服务器进程,设置一个足够大的可用文件描述符数量值。
因为我们的目标是百万tcp连接,所以进程最大可用描述符数量,至少要设置为一百万,但因为进程中其他地方也会使用文件描述符,所以保险起见,我们把这个值设置为两百万。
客户端和服务端都要设置,以下只演示服务器端的设置:

这次设置居然报错了,说该操作不允许,但我们用的是root账号啊,权限应该没问题啊,那会是什么原因呢?
我们到内核里搜下 Operation not permitted 错误对应的错误码:

是 EPERM,在上篇文章 Too many open files 错误深度分析 中我们又提到,ulimit命令对应的系统调用为prlimit64,我们看下这个系统调用,在什么情况下会返回 EPERM 错误码。

经过分析,我们可以找到上图中的代码,当 new_rlim->rlim_max > sysctl_nr_open 时,即使是root用户,也会返回 EPERM 错误码。
new_rlim->rlim_max 是我们想要设置的进程最大可用文件描述符数,即两百万,sysctl_nr_open 对应为 /proc/sys/fs/nr_open 里的值,看下该值的man文档:

由该man文档可知,这个字段限制了进程最大可用文件描述符数,最高可设置到多少,其对root账号也有同样的限制。
我们看下服务端机器该字段的值:

是 1048576,该值小于两百万,所以我们在用ulimit,设置服务进程最大可用文件符数为两百万时,报了 Operation not permitted 错误。
我们先把这个值提高到两百万,然后再设置进程最大可用文件描述符数为两百万:

这次就设置成功了,这样就解决了服务端的 too many open files 问题,客户端也记得设置下。
为了方便,我们把这两条命令写入到 .bashrc 文件中,这样新的ssh连接上来时,这些设置都会生效:

重新启动服务端和客户端测试程序,继续进行百万连接测试。
在这次测试中,服务端没有遇到问题,但客户端报了下面的错误:

我们继续找下该错误对应的内核错误码:

由于该错误是在客户端调用connect时发生的,所以我们看下在connect系统调用中,哪里会返回这个错误码:

经过分析,我们确定为上图中的函数,看上图中的选中行,其返回了 EADDRNOTAVAIL 错误码。
我们之前说过,内核通过 [local_ip, local_port, peer_ip, peer_port] 四元组来唯一确定一个tcp连接。
我们在运行客户端测试程序时,为connect函数指定了 peer_ip 和 peer_port,那connect操作的 local_ip 和 local_port 是从哪里得来的呢?
这两个值,都是内核自动选择的。
内核通过路由表,为要connect的socket选择local_ip,通过上图中的函数,为该socket选择local_port。
上图中 __inet_hash_connect 函数的大致逻辑是,先通过 inet_sk_get_local_port_range 函数,找到备选端口的范围,分别放到 low 和 high 变量里,然后根据一定的规则,在这个范围内 for 循环检测端口,如果某个端口未被使用,则这次connect操作就使用该端口,如果所有端口都被使用了,则返回 EADDRNOTAVAIL 错误码。
也就是说,我们上面运行客户端程序报 Cannot assign requested address 错,是因为内核在为connect操作选择端口时,发现low和high范围内的所有端口都被使用了,此种情况只能返回 EADDRNOTAVAIL 错误。
那 inet_sk_get_local_port_range 函数获取的 low 和 high 的值,在哪里可以查看呢?
在 /proc/sys/net/ipv4/ip_local_port_range 文件里可以查看这两个值。
我们看下客户端机器上这两个值是多少:

由上图可知,low 和 high 的值分别是 32768 和 60999,即内核可以在 [32768, 60999] 范围内为要connect的socket选择本地端口,注意这里的范围是包含关系,即包括 32768 和 60999 两个端口。
所以,在客户端机器上,可被内核选择的端口一共是28232个,这个值正好和上图中客户端测试程序成功建立的tcp连接数相同。
我们来简单总结下,当客户端测试程序调用connect函数建立tcp连接时,内核会为每个connect操作选择一个本地端口,选择范围是 [32768, 60999],因为该范围一共有28232个端口,所以客户端成功建立了28232个tcp连接,之后再尝试建立tcp连接,就开始报 Cannot assign requested address 错误,这是因为此时 [32768, 60999] 范围内的端口都被用光了。
解决这个问题的方式也很简单,就是增大 /proc/sys/net/ipv4/ip_local_port_range 文件里的端口范围:

我们通过echo命令,将端口范围改成了 [1024, 65535],这样客户端测试程序就应该可以建立64512个tcp连接了。
测试看下。
下面是客户端的输出:

下面是服务器的输出:

根据以上两个输出可见,客户端和服务端之间已成功建立起64512个tcp连接,和上面我们计算的一样。
上面提到过,内核用 [local_ip, local_port, peer_ip, peer_port] 四元组来唯一确定一个tcp连接,站在服务端的角度看,local_port值是固定的,即9999,又因为客户端用的是 149.28.222.55 这个peer_ip,连服务器的 144.202.100.11 这个local_ip,所以上面四元组中,local_ip 和 peer_ip 也固定下来了,唯一可变的元素 peer_port,在建立完64512个tcp连接后,可用值也没有了,现在这个四元组中已经不能再建立新的tcp连接了。
我们如果想建立新的连接,只能用新的ip。
在最开始创建云主机时,我们绑定了五个vpc到每台机器,这样它们就额外有了五个内网ip,我们可以用这些ip来建立新连接。
服务端机器上这五个内网ip地址,在文章最开始的机器信息截图里有显示。
现在在客户端机器上启动一个新的测试程序,连接服务器的 10.12.96.3:9999 地址。
新客户端的输出:

服务端输出:

由上可见,连接到 10.12.96.3:9999 地址的客户端测试程序,又建立了64512个连接,现在服务端总共建立了 129024 个tcp连接。
再继续开客户端测试程序,连接服务端的 10.12.112.3:9999 地址。
这次在创建两万七千多连接时,服务器因为内存不足,直接kill掉了很多进程,包括服务端测试进程,ssh进程等,之后ssh就连不上了,此时只能重启服务器。
重启完服务器后,查看其在空闲状态下可用内存约为600MiB,上面创建的近16万个tcp连接消耗完了这600MiB,平均每个tcp连接消耗内存约为4KiB。
我们想要创建一百万tcp连接,那光这些tcp连接的内存消耗就约为4GiB,再加上操作系统会使用约500MiB内存,所以作为服务端的测试机器,至少要有5GiB以上的内存,保险起见,我们购买个8GiB内存的机器当作服务器。
因为客户端机器最多只能创建约,每个ip地址6.5万 * 6个ip地址 = 39万tcp连接,这些tcp连接大约需要消耗1.5GiB内存,外加操作系统会使用约500MiB内存,所以客户端机器至少要有2GiB以上内存,保险起见,我们选择4GiB内存的机器作为客户端测试机,因为我们要建立100万连接,所以需要购买3台这样的机器。
在销毁掉之前购买的机器,然后购买完新机器后,我们按照之前的流程对这些机器进行设置,比如关闭防火墙,提高进程最大可用文件描述符数到200万,客户端机器还要增大 /proc/sys/net/ipv4/ip_local_port_range 文件里的端口范围,做完这些之后,我们就可以继续开始测试了。
不过在测试之前,我们先看下新购买的服务端机器的信息:
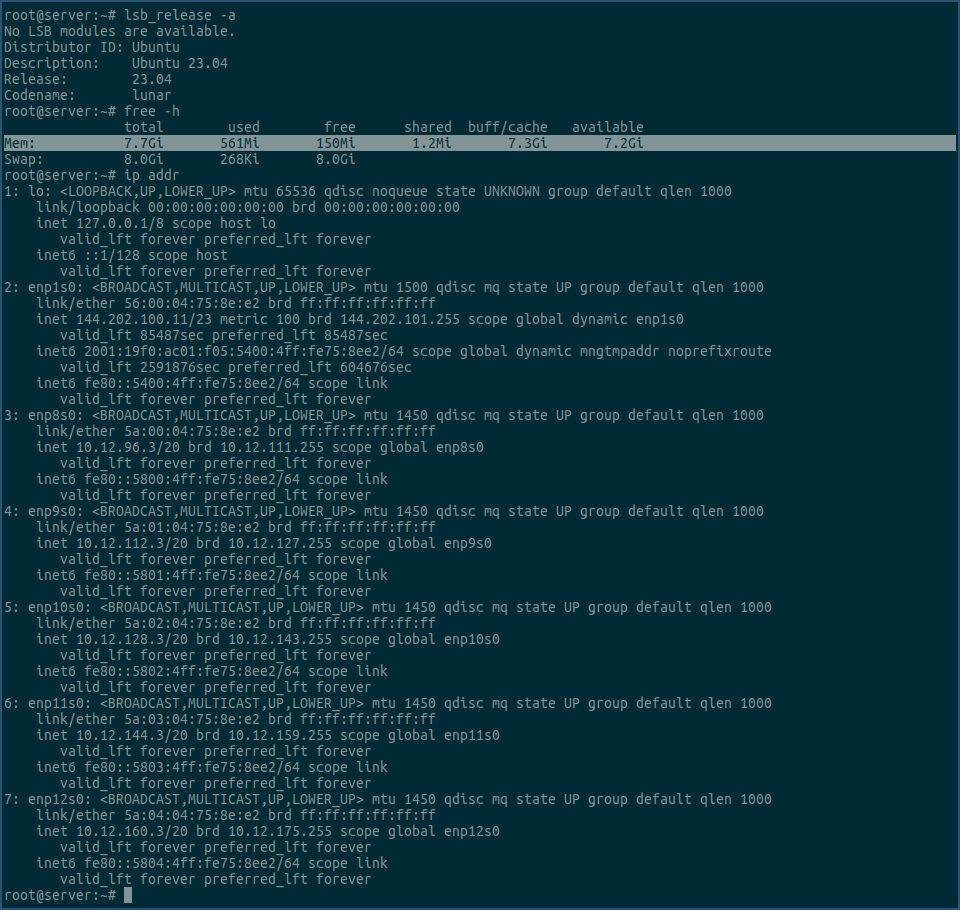
由上图可以看到,新机器的ip地址都没有变,目前机器在空闲状态下,已用561MiB内存,这个要注意下,等后面建立百万tcp连接后,再看下用了多少内存,这样可以精确算下每个tcp连接使用多少内存。
继续按照之前的流程,开启客户端测试程序,对服务器创建tcp连接。
这次很顺利的创建了,3个ip地址 * 每个ip地址64512个tcp连接 = 193536个tcp连接,看服务器控制台的输出:

我们看下当前服务端机器内存的使用情况:

由上图可见,当前已用内存为 1265 MiB,而没开服务端测试程序时,内存使用为 561 MiB,所以 193536 个tcp连接总共消耗了 704 MiB内存,平均每个tcp连接消耗约 3.7 KiB内存,和之前的计算差不多。
我们继续在客户端机器上开启3个测试程序,连接服务器上剩余的3个ip:

这次也比较顺利,所有连接都正常建立,现在这台机器上的6个ip都被使用了,每个ip创建了 64512 个tcp连接,一共创建了 387072 个tcp连接。
看下现在服务器的内存的使用情况:

一共使用了 2009 MiB内存,除去初始状态下系统使用的 561 MiB内存,387072个tcp连接一共使用了 1448 MiB内存,平均每个tcp使用3.8 KiB,和之前计算接近。
现在这台机器上的6个ip,以及每个ip关联的6万多个端口都被使用了,该机器已经达到对服务器可创建tcp连接的上限。
我们用同样的方式,在另外两台客户端测试机上,也开启这么多的tcp连接。
这是3台客户端机器tcp连接都跑满后,服务端控制台的最终输出:

连接总数正好等于,3台机器 * 每台机器6个ip * 每个ip可用64512个端口 = 1161216 个tcp连接,约等于116万tcp连接数。
看下当前服务器内存使用情况:

当前一共使用了 4797 MiB内存,除去初始状态下系统使用的 561 MiB内存,1161216 个tcp连接一共使用了 4236 MiB内存,平均每个tcp使用 3.7 KiB,和之前计算接近。
至此,我们单机实现百万tcp连接的目标就达成了。
0x04 总结
下面我们总结下,从零开始实现单机百万tcp连接,对机器有什么要求,以及要对机器做什么设置。
首先,为了测试方便,要先把防火墙关掉:systemctl disable --now ufw.service
其次,要提高测试进程的最大可用文件描述符数量:echo 2000000 > /proc/sys/fs/nr_open && ulimit -n 2000000
接着,客户端机器还要增大内核备选端口范围:echo 1024 65535 > /proc/sys/net/ipv4/ip_local_port_range
最后,是内存要求,服务端机器要5GiB以上,客户端机器要2GiB以上,这是极限情况,测试时最好比这个大一些。
另外,我们通过这次测试,也得出了一个结论,即一个tcp连接约消耗4KiB内存。
好了,本篇文章的内容就这些,希望对你有所帮助。
0x05 其他
如果有对linux及linux内核感兴趣的,可以扫描右侧二维码添加我的微信。
另外,我开设了一门 linux内核启动流程源码分析 课程,有对内核源码感兴趣的,欢迎报名。