0x01 前言
接上一篇文章 Too many open files 错误导致服务器死循环 ,我们继续来讲下该错误产生的原因,及各种解决方案。
注:文件描述符的英文为 file descriptor,简写为fd,如无特殊说明,下文就用fd代指文件描述符。
0x02 这个错误是在哪里产生的?
该错误是在内核里定义的,所以自然也是在内核里产生的:
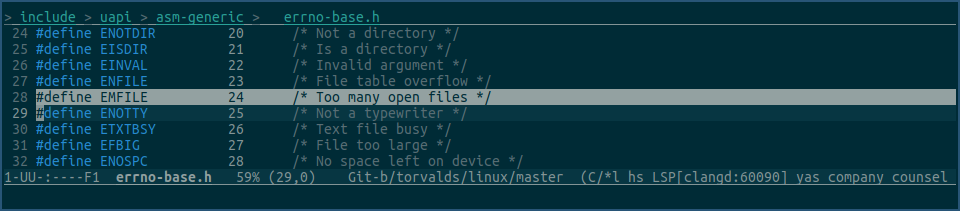
我通常见到的 too many open files 错误,其实就是内核返回了 EMFILE 错误码。
0x03 它的产生原因是什么?
本质上来讲,产生这个错误的原因,就是内核为进程分配的fd不够用了。
在linux的世界里,一些皆文件,当我们做打开文件、创建socket、创建epoll实例等操作时,内核会把这些创建的对象,都封装成一个struct file实例,然后将其放到进程的已打开文件数组里,而数组的下标,就是fd,也就是我们常说的文件描述符。
这个fd会随着上述系统调用的结束,返回给用户层,用户层程序后续就可以用其他的一些系统调用,比如read/write,来操作这个fd,也就是操作这个fd对应的内核文件、socket、及epoll实例了。
这就是linux世界里的一切皆文件。
由此可见,fd是一种非常强大且核心的系统资源。
为了防止fd被滥用,内核为每个进程做了一个最大可使用fd数量限制,该值存放在进程实例字段 struct task_struct -> signal -> rlim里:

其实内核不单能对进程可使用fd做限制,还能对进程其他可使用资源做出限制,所以在上图中,rlim字段是个数组,而数组的下标,就是资源类型。
限制fd的资源类型是 RLIMIT_NOFILE,其值为:

我们继续看下 struct rlimit 结构体的定义:

该结构体里定义的是两个值,而不是一个。
以fd限制类型为例,rlim_cur表示当前进程最大可使用的fd数量值,rlim_max表示在无相应权限的情况下,rlim_cur最高能调高到多少。
比如你不是root用户,但你想调高某进程fd资源的rlim_cur值,你最高可调高到rlim_max。
进程当前各类资源的限制值,可通过 cat /proc/pid/limits 查看,例如查看1号进程的各项资源limit值:
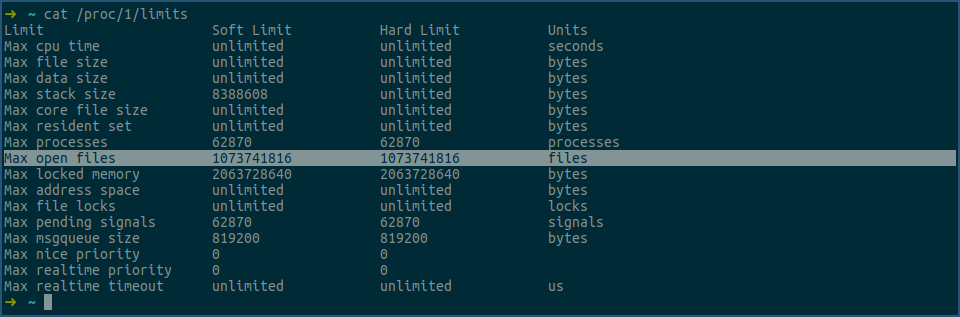
其中,上图中选中行就是 RLIMIT_NOFILE,即fd资源限制类型,对应的 struct rlimit 结构体里的值,其中Soft Limit 就是 rlim_cur 的值,Hard Limit 就是 rlim_max 的值。
执行 cat /proc/pid/limits 命令时,对应调用的内核代码为:
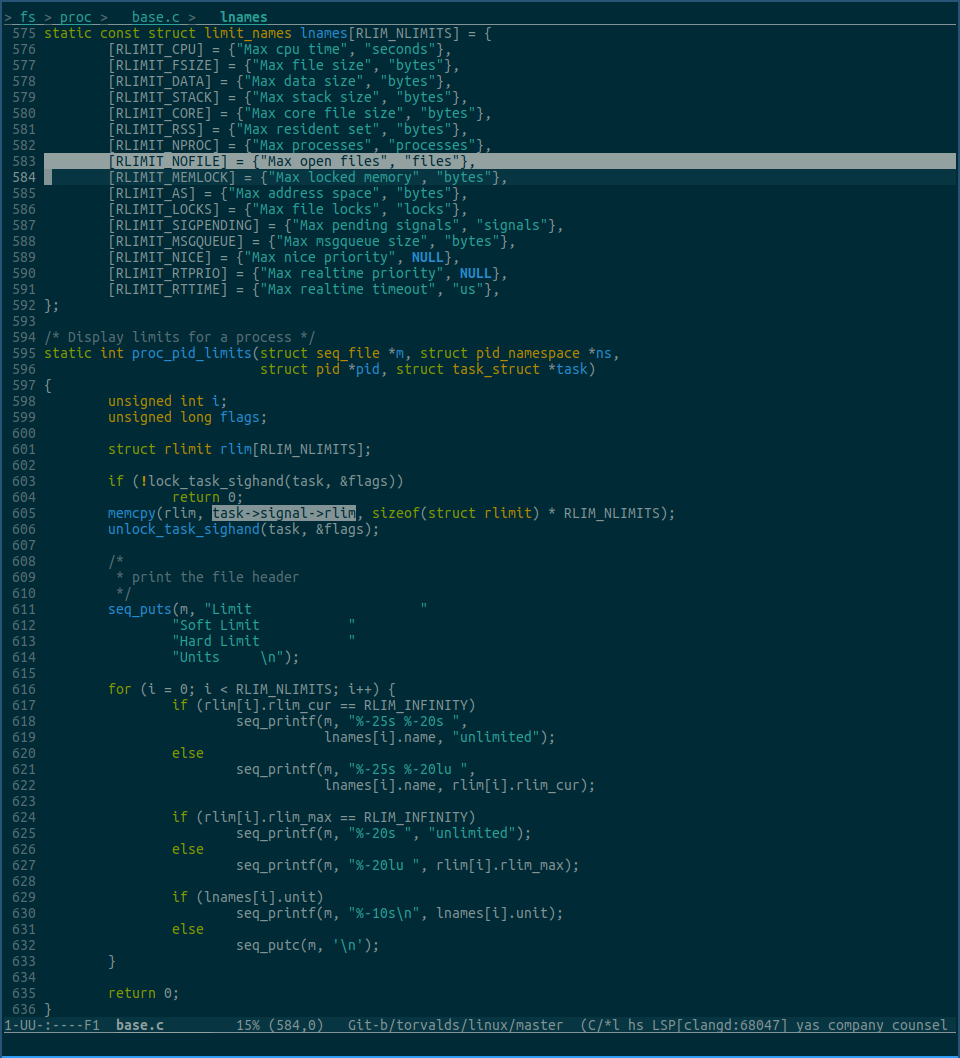
由上图中的选中部分可知,cat /proc/pid/limits 命令输出的各项limit值,就是从task->signal->rlim里获取的,而 Max open files 行里的数据,对应的就是task->signal->rlim[RLIMIT_NOFILE] 里的值。
当进程要求内核为其创建一个广义的file对象时,比如创建一个socket,内核会调用以下函数,获取一个当前进程还未使用的fd:

在该函数的内部,会调用 rlimit(RLIMIT_NOFILE) 获取当前进程最大可使用的fd数量,rlimit(RLIMIT_NOFILE) 最终会调用到以下函数:

由上图可见,进程最大可使用的fd数量,就是从 task->signal->rlim[RLIMIT_NOFILE].rlim_cur 里获取的,这个和我们上文讲的是一样的。
当通过 rlimit(RLIMIT_NOFILE) 获取到当前进程fd的最大可用数后,get_unused_fd_flags 会继续调用其他函数,来找一个还未被当前进程使用的fd,该函数最终会调用到下面的函数:
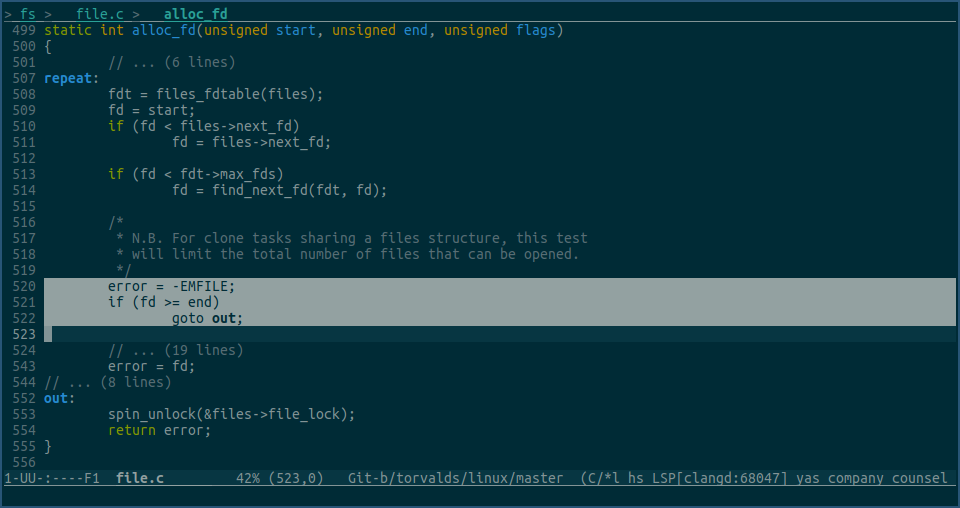
其中函数参数end,就是上面通过 rlimit(RLIMIT_NOFILE) 获取的值。
上图中选中行之前,就是在为当前进程找一个还未被使用的fd,当找到之后,就使用选中行逻辑,判断该fd是否超过了最大可使用fd数量的限制,如果超过了,就goto到out,然后返回error,而这个error,就是EMFILE,即 too many open files 错误。
以上就是该错误产生的原因。
0x04 如何解决这个问题?
解决这个问题的根本方式,就是调高进程字段 task->signal->rlim[RLIMIT_NOFILE].rlim_cur 里的值。
linux内核提供了两个系统调用,可以修改 task->signal->rlim 数组里的值,它们分别是 setrlimit 和 prlimit64:
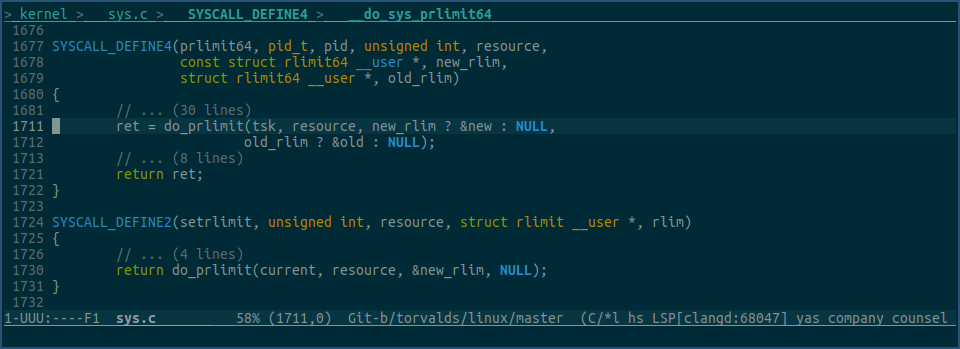
setrlimit是设置当前进程的各项limit值,prlimit64功能更强大点,还可以指定进程id,不过这两个系统调用最终都是调用的do_prlimit:
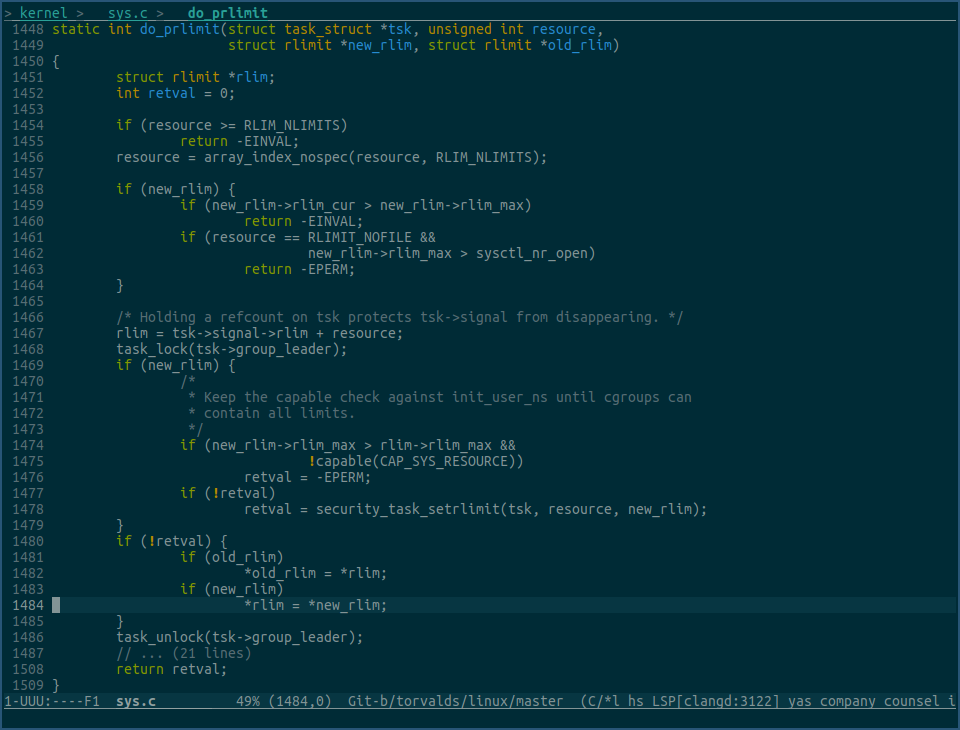
上图do_prlimit函数中,在最终将新的rlimit赋值到 task->signal->rlim 数组中前,该函数做了各种安全验证。
比如,1459行要求新的rlim_cur值不能大于新的rlim_max值。
比如,1461和1462行要求,如果该资源类型是RLIMIT_NOFILE,则新的rlim_max值不能超过sysctl_nr_open。
比如,1474和1475行要求,如果新的rlim_max值大于当前的rlim_max值,当前进程必须拥有 CAP_SYS_RESOURCE 权限。
以上是内核中系统调用的实现,在用户程序层面,系统库比如glibc,提供了相应的同名函数,使得我们可以用编程的方式,来调整这些进程资源限制值。
这两个系统调用,是调整进程资源限制值的唯一方式,其他的任何方式,都是通过调用这两个系统调用来实现的。
0x05 通过prlimit命令修改进程最大可使用的fd数量
看个例子:
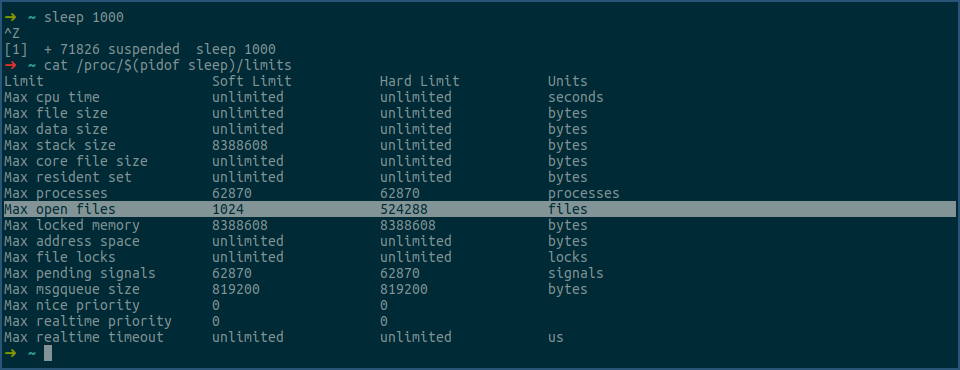
在上图中,先用sleep命令创建一个进程,然后再将该进程切换到后台,之后再用cat命令查看其最大可使用的fd数量。
看上图中的选中行,其中soft limit列表示该sleep进程最大可同时打开的文件数为1024个,hard limit列表示,在不使用root权限的情况下,该sleep进程的soft limit值,最大可调高到524288。
用prlimit命令修改下这两个值:
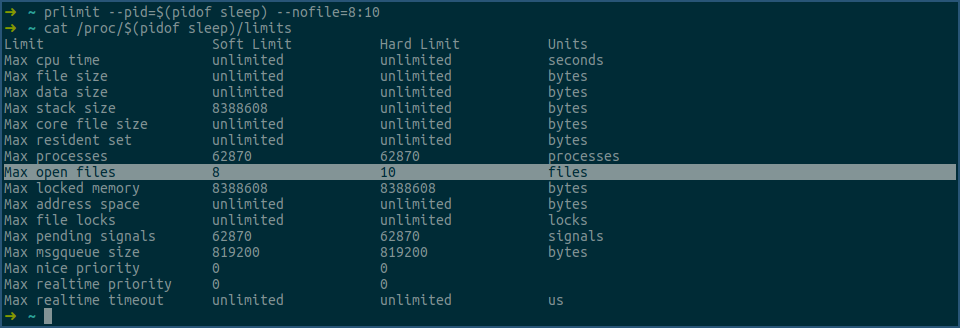
由上图可见,sleep进程max open files行的soft limit被修改成了8,hard limit被修改成了10,修改已生效。
看下prlimit程序对应的修改代码:
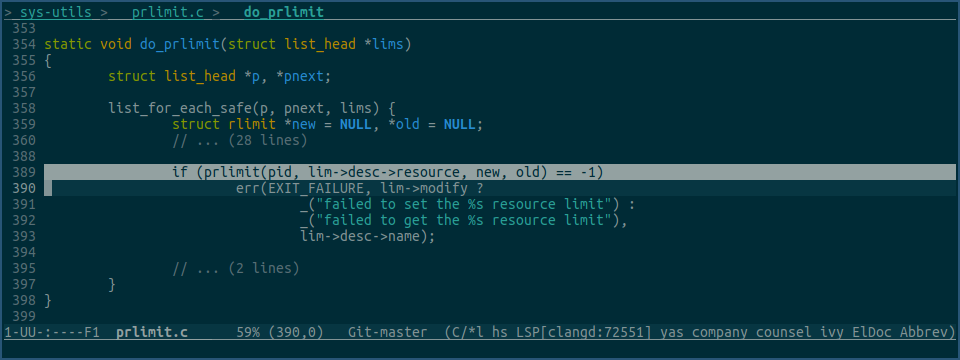
由上图可见,prlimit命令是通过glibc的prlimit函数来修改fd限制值的。
再看下glibc中的prlimit函数:
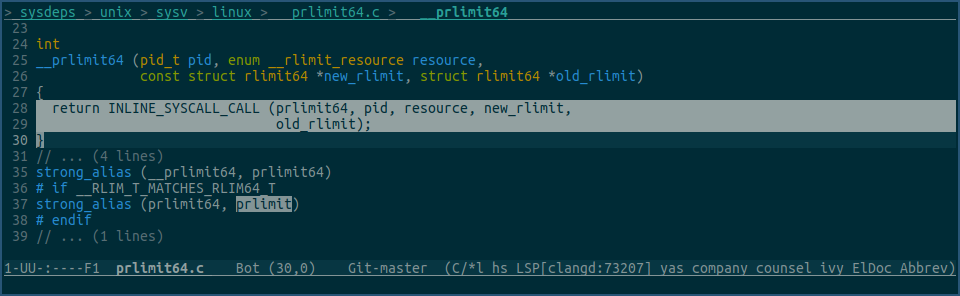
由上图可见,它又是通过调用prlimit64系统调用来修改fd限制值的。
0x06 使用ulimit命令修改进程最大可使用的fd数量
另一个我们比较常见的,修改进程最大可使用fd数量的命令是ulimit,还是先看个例子:
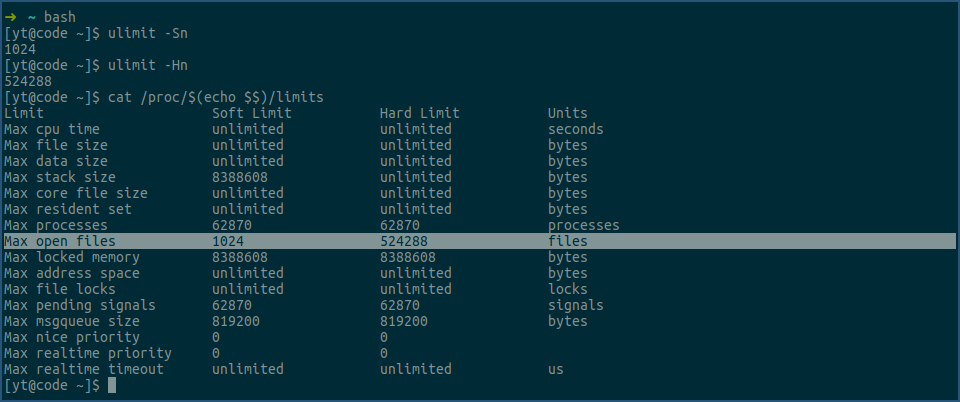
因为ulimit是bash的一个内置命令,所以在上图中,我们先开一个新的bash,然后再用ulimit -Sn及ulimt -Hn命令,查看当前bash进程fd的soft limit 和 hard limit 值,接着,我们又用cat命令查看bash进程对应的limits文件,确认ulimit命令输出的值是正确的。
下面我们通过ulimit命令,修改进程的fd资源限制值:
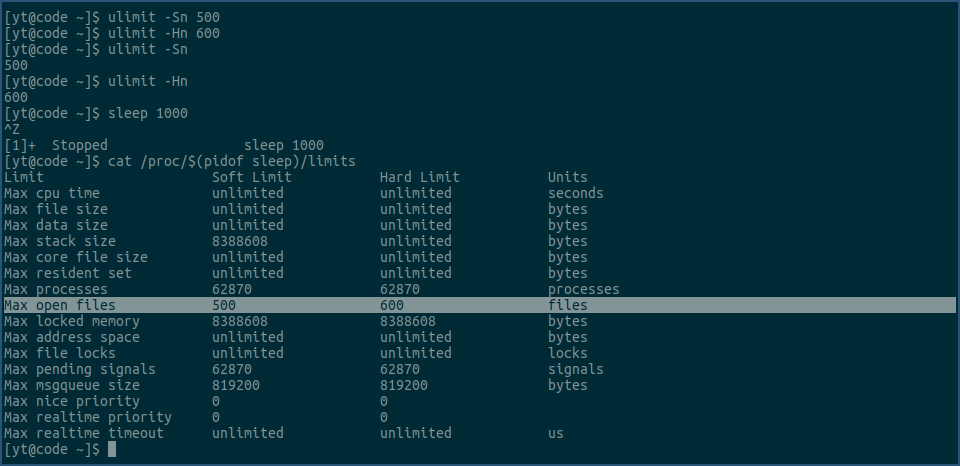
上图中,我们先用ulimit命令,修改当前bash进程fd资源的soft limit为500,hard limit为600,然后查看确认其已生效。
然后,我们启动了一个sleep进程,并让其进入后台。
接着,我们用cat命令查看该sleep进程fd资源的soft limit和hard limit值,它们分别是500和600,说明我们用ulimit命令设置的fd资源限制值,在sleep进程里是生效的。
接下来我们看下ulimit命令的内部实现:
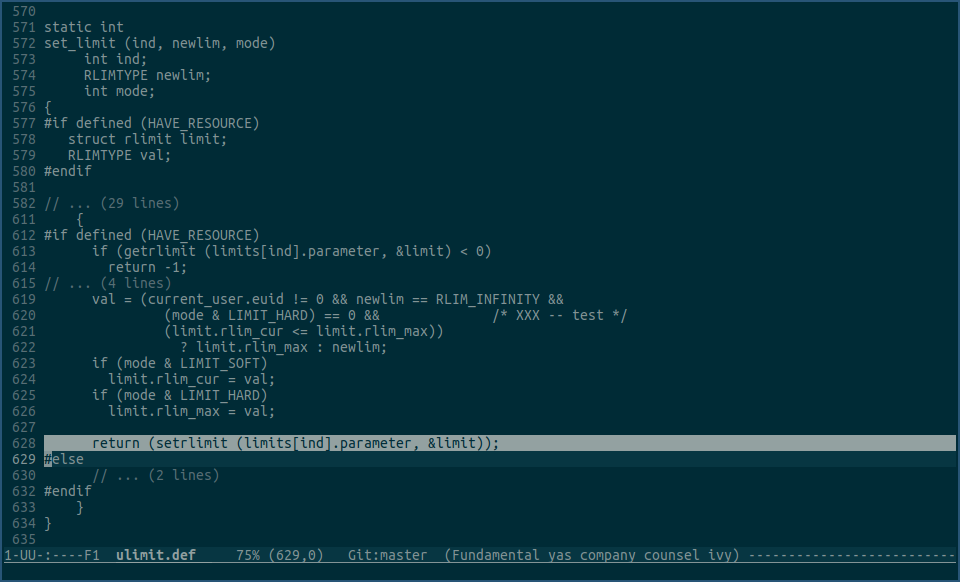
由上图可见,ulimit命令里设置rlimit值,是用的glibc的setrlimit函数。
看下glibc里的setrlimit函数:
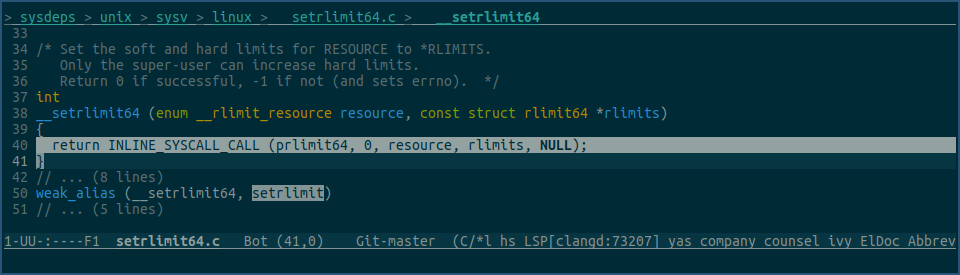
由上图可见,glibc的setrlimit函数,使用的还是prlimit64系统调用,不过这次的pid参数传入的始终是0,即为当前进程设置rlimit值。
这个例子中其实还有个疑问,不知道大家注意到没有。
ulimit命令最终调用的prlimit64系统调用,是为当前bash进程,设置的fd资源rlimit值,这个值在bash进程中生效是没问题的,那为什么在sleep进程中也生效了呢?
这是因为进程的资源限制值,即task->signal->rlim数组,是会被子进程继承的,因为sleep进程是bash进程的子进程,所以它继承了bash进程中的fd资源限制值。
看下内核中对应的继承代码:
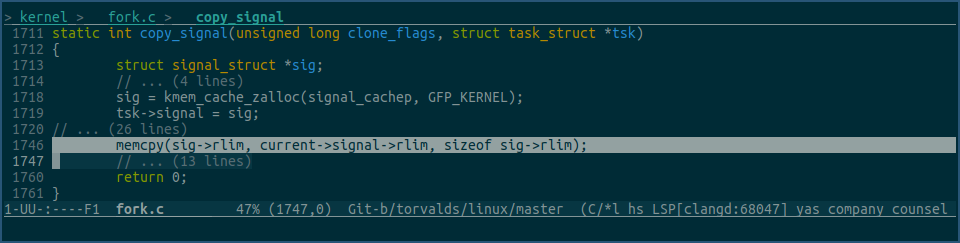
当bash通过fork系统调用,创建子进程时,其进程内的task->signal->rlim数组值,会被拷贝到子进程的task->signal->rlim数组里,这样,虽然ulimit命令修改的是bash进程的资源限制值,但由bash进程启动的子进程里,也会继承这些值。
0x07 通过 /etc/security/limits.conf 文件修改进程最大可使用fd数量
之前设置fd最大可用数量的方式都是临时的,当重启进程,或重开一个新的bash再执行相同的程序后,之前的设置都会失效。
但是,通过修改 /etc/security/limits.conf 文件的方式来设置fd资源限制值,是会永久生效的。
还是先看个例子:

我们先将 /etc/security/limits.conf 文件修改成以上内容,然后退出重新登陆。
登陆后,用ulimit命令查看下当前bash的fd资源限制值:

由上图可见,/etc/security/limits.conf 文件里的修改,已对bash生效,之后由bash运行的程序,也都会继承该值。
那为什么修改 /etc/security/limits.conf 文件会影响到bash进程呢?
这个还比较复杂。
linux下的很多程序,比如用于终端登陆的login,用于ssh登陆的sshd,用于临时获取root权限的sudo,都要在某些时候进行权限验证,如果每个程序都自己单独写自己的权限验证逻辑的话,那不仅费时费力,还容易出bug。
为此,linux系统下产生了一套完整的权限验证系统库pam,其全称为 Pluggable Authentication Modules。
上面说到的login, sshd, 及sudo程序,都接入了这个库来进行权限验证,使用它的好处是,所有需要权限验证的程序,现在都有了一个统一的地方,及统一的规则,可用配置的方式,来管理对应程序的权限验证过程。
而且pam的设计非常巧妙,它本身是模块化的,管理人员可以将不同的程序,配置成使用不同的验证模块及验证逻辑,来实现不同的权限验证需求。
对于login程序,其pam配置文件为 /etc/pam.d/login。
对于sshd程序,其pam配置文件为 /etc/pam.d/sshd。
对于sudo程序,其pam配置文件为 /etc/pam.d/sudo。
以此类推。
我们以login程序为例,看下其配置文件长什么样子:
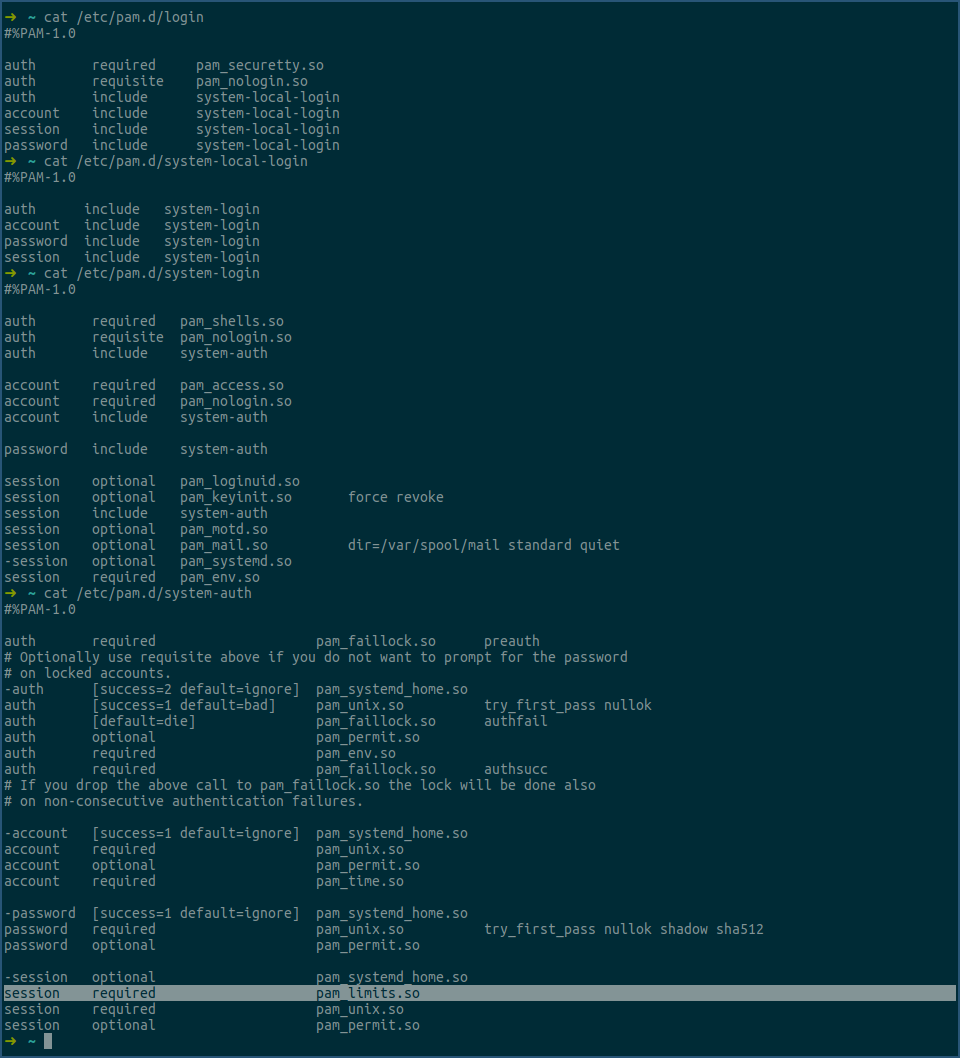
我们先看上图中第一次cat命令的输出,其中第3列中以so结尾的,就是pam 模块,即实际参与权限验证的共享库。
第2列中,如果是include,表示引入其他文件,在第一次cat命令输出中,其引入了system-local-login。
我们再用cat命令,看下system-local-login的内容,可以看第二次cat的输出,又是继续引入system-login。
继续用cat命令查看system-login文件,即第三次cat输出,这次就配置了很多用于权限验证的pam模块,以及又incude了system-auth。
继续用cat命令看下system-auth,即第四次cat输出,这里有一个非常重要的,涉及到本篇文章的模块 pam_limits.so。
当我们启动电脑后,login程序运行,让你可以在终端登陆。
在你输入了用户名密码后,login程序就会调用pam库来进行权限验证,pam先找到login程序的验证配置文件,即 /etc/pam.d/login,解析其中配置了哪些模块,即以so为结尾的那些共享库,然后就开始依次调用这些模块来进行权限验证。
对于本篇文章来说,我们关心的就只有 pam_limits.so 这个pam模块。
pam_limits.so 模块在运行时,它会先读取 /etc/security/limits.conf 配置文件里的内容,然后根据其配置,为当前进程,在本例中就是login进程,设置rlimit值。
其对应的设置代码为:
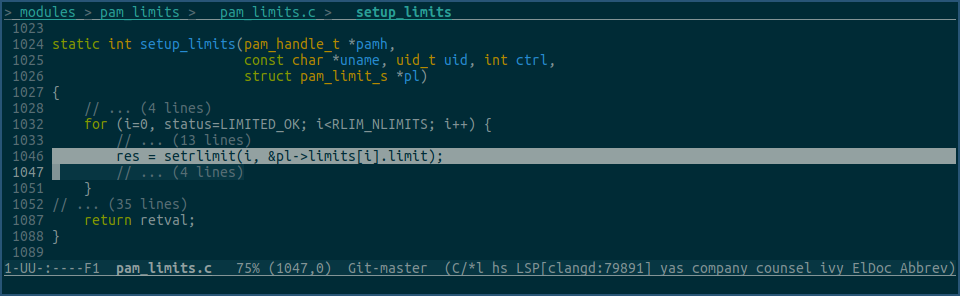
又因为上面我们讲过,进程的各种rlimit值是会被子进程继承的,所以login进程在登陆验证成功后,启动的子进程bash,自然也就有了相同的rlimit值。
我们还可以通过以下方式,进一步验证下这个过程:
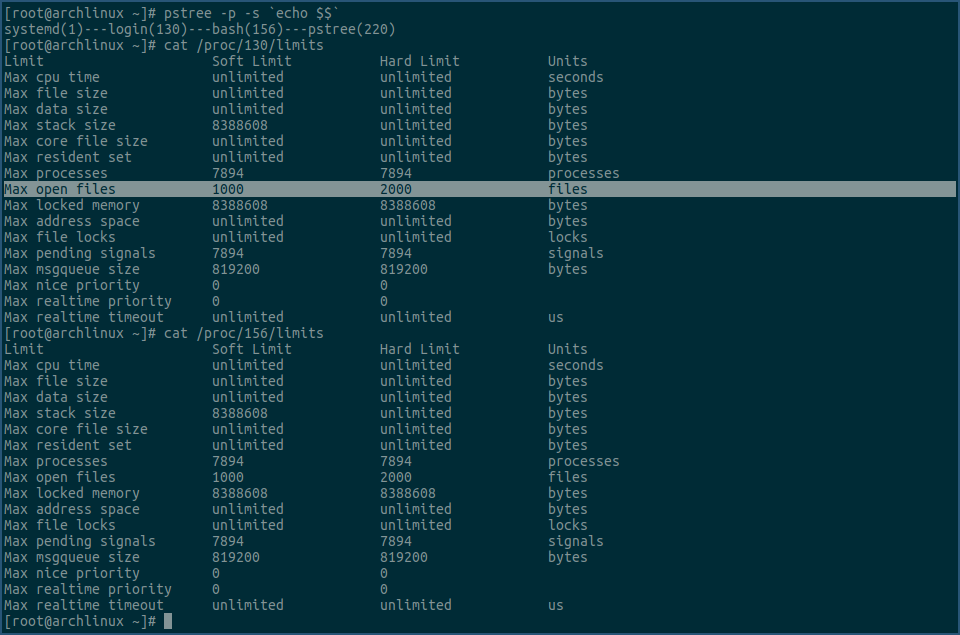
上图中,我们先用pstree命令,确认login进程确实是bash进程的父进程,然后再用cat命令,查看login进程的各项rlimit值,其中看max open files 那一行,和bash进程的相同行数值一样,都是1000和2000,这个也和我们在 /etc/security/limits.conf 文件里配置的一样。
现在大家就应该明白了,本节最开始展示的那个示例中,为什么在 /etc/security/limits.conf 文件里设置nofile值,会在bash里生效了吧。
对于sshd以及sudo,都是同样的逻辑,只要其对应的pam配置里配置了pam_limits.so 模块,然后再在/etc/security/limits.conf里配置了相应的rlimit,你在ssh登陆后或者执行sudo命令时,就都有了相应配置的rlimit值。
0x08 为通过systemd的service方式启动的进程设置最大可使用fd数
linux里还有一部分进程,是以systemd的service方式启动的,这部分进程用以上方式,都无法很好的为其设置最大可使用fd数。
不过,在systemd相关配置里,已对这些进行了内置支持,使用起来非常方便。
还是看个例子:
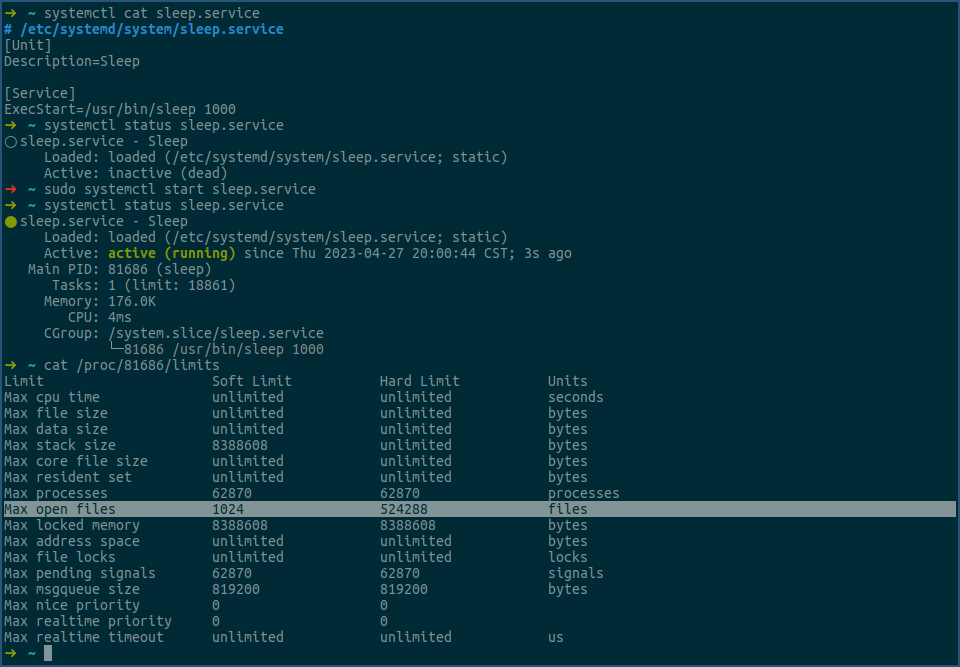
上图中,我们先创建了一个sleep.service,然后将其启动,之后查看对应sleep进程的max open files值。
这些值是在没有特殊设置的情况下,以systemd的service方式启动进程的默认值。
接下来,我们修改 /etc/systemd/system.conf 配置文件,将 DefaultLimitNOFILE 值设置为 2000:20000:

然后,我们用systemctl daemon-reload命令重新加载下配置,最后再重启下sleep.service:
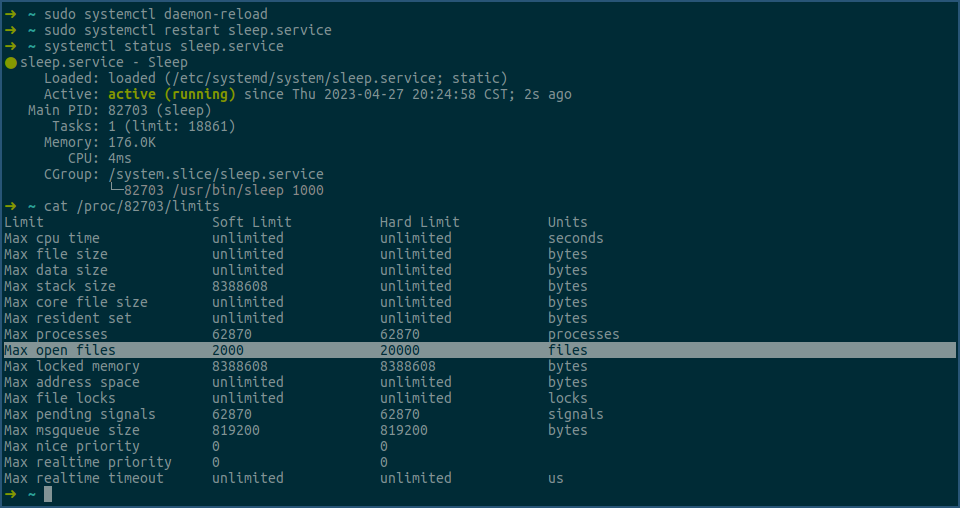
由上可见,新的sleep进程的max open files值已经被修改成了2000和20000,即 /etc/systemd/system.conf 文件中的配置生效了。
/etc/systemd/system.conf 文件中的 DefaultLimitNOFILE 字段,是一种全局配置,会影响所有service,如果我们不想要这种全局配置,而是想为某个service单独配置其最大可用fd数量值,我们可以在对应的service配置文件中,配置 LimitNOFILE 字段。
还是以sleep.service为例:
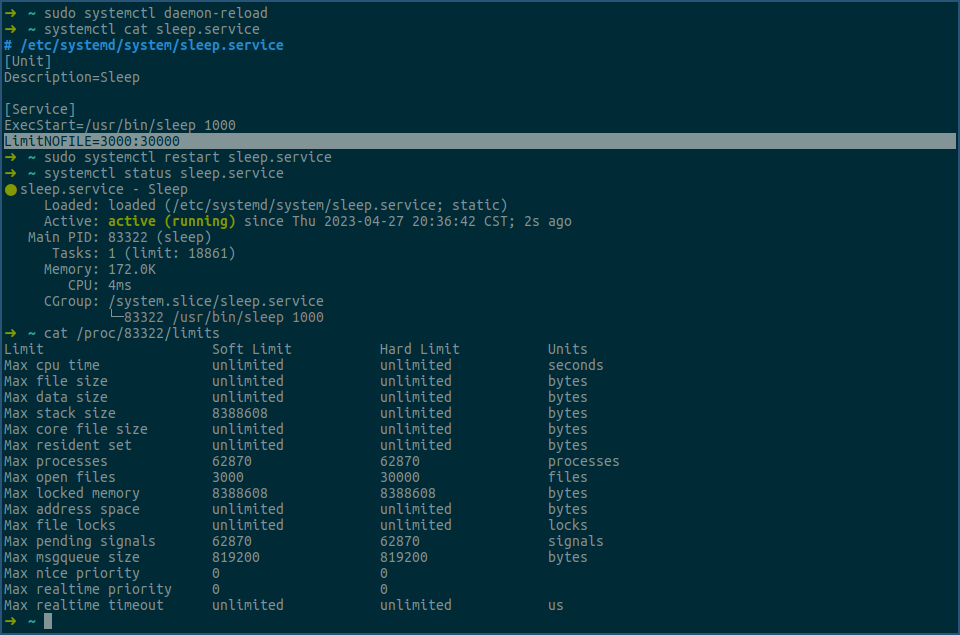
在上图中,我们先在 sleep.service 配置文件中加了一行 LimitNOFILE,即图中的选中行,然后我们执行 systemctl daemon-reload 命令重新加载下配置,之后我们用 systemctl cat sleep.service 命令确定改动已生效,最后我们重启sleep.service。
接下来,我们用cat命令查看新的sleep进程各项rlimit值,其中 max open files 行已经变成了3000和30000,说明在sleep.service里的设置的 LimitNOFILE 确实生效了。
systemd中对应设置service的rlimit代码为:
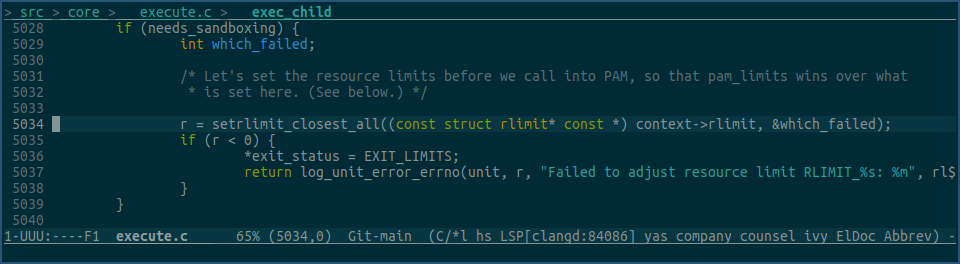
上图中setrlimit_closest_all 最终会调用以下代码:

由图可见,其最终也是使用setrlimit,来设置以service形式启动进程的各项rlimit值的。
0x09 结语
本篇文章深入介绍了 too many open files 错误产生的原因,以及该问题的各种解决方式,同时我们也用各种示例、各种源码,来了解整个底层原理。
下一篇文章中,我们会以从0开始创建百万tcp连接的方式,来实践下本篇文章中介绍的各种理论,同时我们还会看下在这过程中遇到的其他问题。
敬请期待。
0x0a 其他
如果有对linux及linux内核感兴趣的,可以扫描右侧二维码添加我的微信。
另外,我开设了一门 linux内核启动流程源码分析 课程,有对内核源码感兴趣的,欢迎报名。